LohCG computational performance
This page discusses the computational performance of the LohCG solver. A first series of timings demonstrate that scalability is ideal up to 65K CPUs, while a second one shows good strong scaling up to 196K CPU cores.
Strong scaling of computation
Using increasing number of compute cores with the same problem measures strong scaling, characteristic of the algorithm and its parallel implementation. Strong scalability helps answer questions, such as How much faster one can obtain a given result (at a given level of numerical error) if larger computational resources were available. To measure strong scaling we ran the Lid-driven cavity using a 794M-cell mesh (133M points) on varying number of CPUs for a few time steps and measured the average wall-clock time it takes to advance a single time step. The figure below depicts timings measured on the LUMI computer.
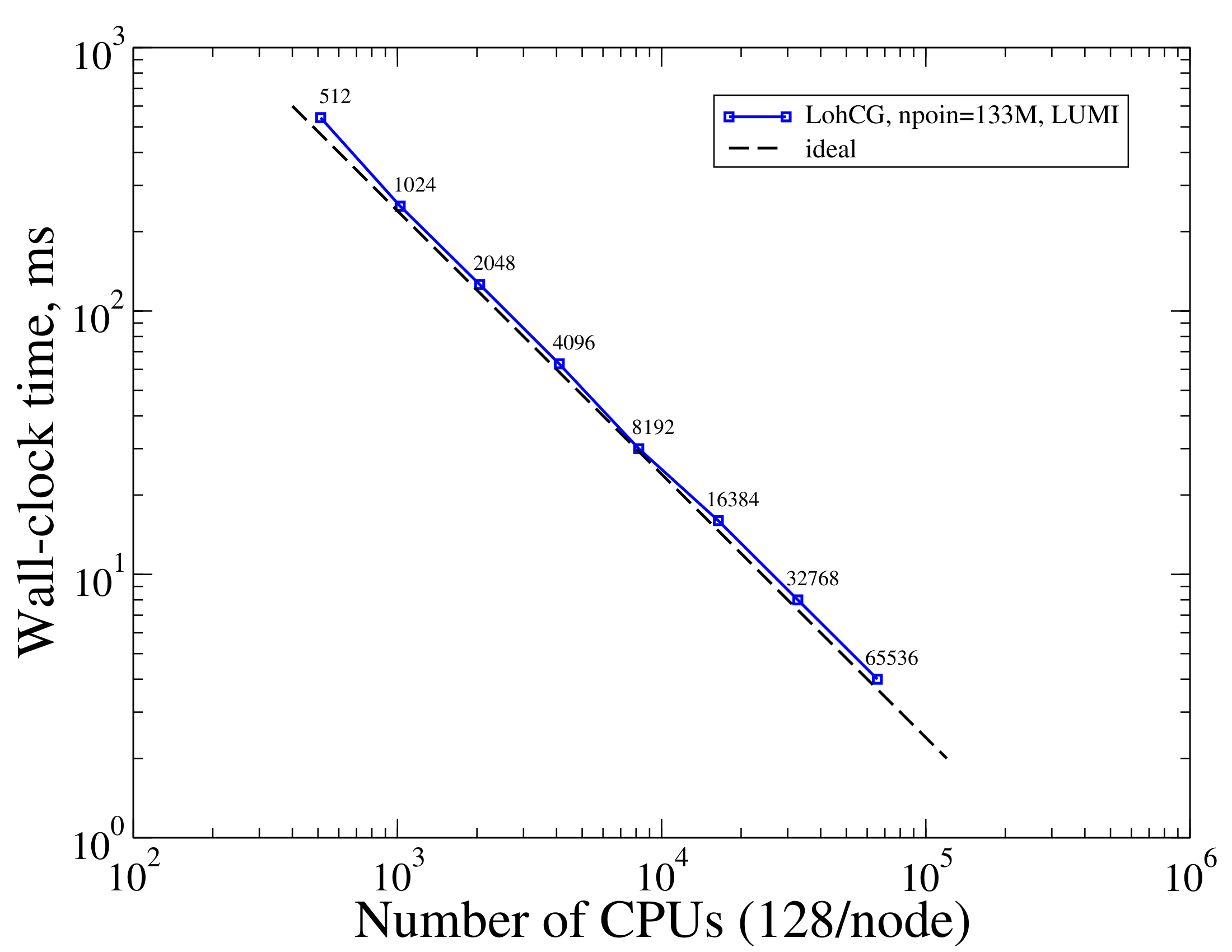
The figure above shows that the LohCG solver scales ideally up to 65K CPU cores.
Strong scaling of computation – second series
Approximately a month after the above data, the same benchmark series has been rerun on the same machine, using the same code computing the same problem using the same software configuration. The results are depicted below.
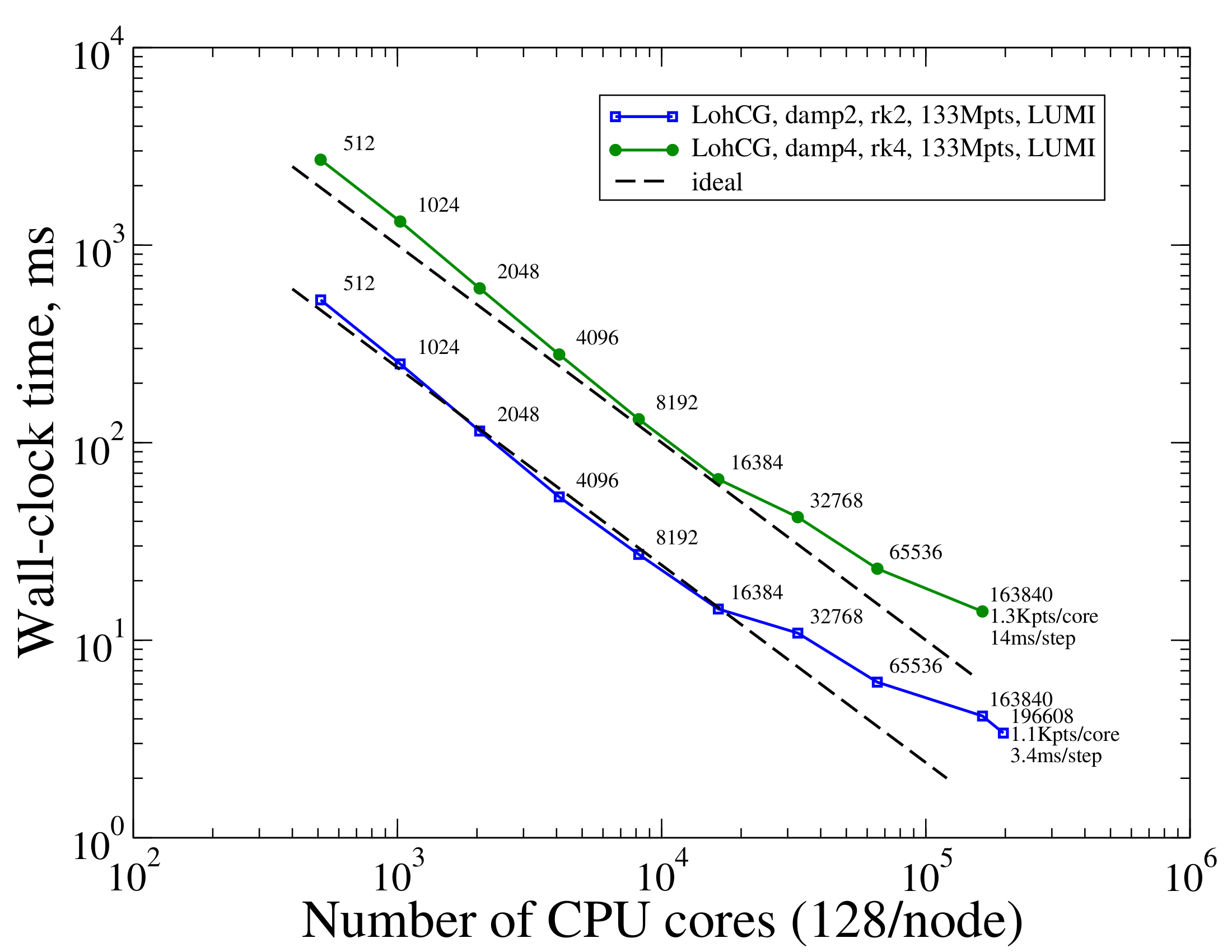
The above figure depicts two series each combining different types of advection stabilization and different number of stages of explicit (Runge-Kutta) time stepping. The blue series on both figures are comparable.
This figure shows that though strong scaling is not ideal, using larger number of CPUs still significantly improves runtimes up to and including the largest run employing 196,608 CPU cores. Considering the mesh with 794,029,446 tetrahedra connecting 133,375,577 points, this corresponds to approximately 1,000 mesh points per CPU core on average. Advancing a single (2-stage) time step (rk2 with damp2 stabilization) takes 3-4 milliseconds of wall-clock time on average.
Comparing the blue series in the two figures also reveals that they differ above approximately 16K CPUs. We believe this may be due to different configurations of hardware, operating system, the network interconnect and/or it could also be due to different background loads between the two series.